以Selenium IDE建立測試案例:圖片延緩載入
以Selenium IDE建立測試案例:圖片延緩載入

圖片延緩載入是我近日在「布丁布丁吃什麼?」新增的功能。在使用者開啟網頁時,此功能會停止載入瀏覽範圍外的圖片,當瀏覽範圍移至該圖片時,該圖片才正式進行載入動作。
現在我要撰寫一個測試案例(Test Case),檢查圖片延緩載入功能是否能夠正確地運作。
測試目的
- 確定瀏覽範圍外的某張圖片沒有載入。
- 將某張沒有載入的圖片移至瀏覽範圍內,確定圖片有正確載入。
測試步驟大綱
圖片延緩載入測試指令編號清單
| 功能 | 測試指令編號 |
| A. 圖片延緩載入功能 | |
| 1. 讀取網頁與初始化 | A1-1 A1-2 |
| 2. 確認瀏覽範圍外圖片沒有載入 | A2-1 |
| 3. 移動瀏覽範圍到該圖片,確認圖片載入 | A3-1 A3-2 |
圖片延緩載入測試指令清單
| 測試指令編號及測試目的 | 初始狀態 | 操作 | 預期輸出資料或結果 |
| A1-1 開啟指定頁面 | 使用者在瀏覽器中開啟指定頁面網址 | 瀏覽器開啟指定頁面網址 | 指定頁面正確載入,JavaScript皆有正確初始化 |
| A1-2 等待圖片延緩載入初始化 | 接A1-1 | 確認瀏覽範圍外的圖片出現original屬性 | 瀏覽範圍外的圖片出現original屬性 |
| A2-1 確認瀏覽範圍外的圖片沒有載入 | 接A1-2 | 確認瀏覽範圍外的圖片的src屬性不是圖片正確的網址。(實際上只是佔位圖片) | 瀏覽範圍外的圖片的src屬性不是正確的圖片網址 |
| A3-1 觸發圖片延緩載入功能 | 接A2-1 | 網頁捲軸往下移動到範圍外的圖片位置 | 觸發圖片延緩載入功能 |
| A3-2 確認圖片正常載入 | 接A3-1 | 等待圖片載入正確的圖片網址 | 圖片正確的網址順利載入 |
建立測試指令
由於這個功能並不是像Selenium IDE介紹影片中只是單純的網頁點擊,所以在此並不使用Selenium IDE的錄製(Record)功能,而是純手工建立一條一條的測試指令。
詳細的指令內容,請參考Selenium的指令說明。以下我僅以會使用到的部分來進行說明。
設定等待時間
- Commend: setTimeout
- Target: 60000
- Value:
下文中每條測試指令都會以上述的方式來呈現。Commend、Target、Value分別對應到Selenium IDE中的三個欄位,見下圖:

通常Target會作為指令第一個參數輸入,而Value會作為指令第二個參數來輸入。Target不一定每次都是元素定位器,要視指令需要的參數而定。
Selenium IDE會在下方Reference裡說明指令的用途。在此我也會簡單說明初次使用的指令用法。

setTimeout(timeout)
參數:
timeout - 逾時限制時間,單位是毫秒。超過逾時限制時間的話,該指令會發生錯誤。
使用「open」(開啟網頁)與「waitFor」開頭的指令時,都會用到逾時限制時間的設定。當該指令超過逾時限制時間,則該指令會發生錯誤。預設的逾時限制時間是30秒。舉例來說,使用「open」指令開啟網頁時,當網頁開啟超過30秒仍未完成,則「open」指令會發生錯誤。
由於「布丁布丁吃什麼?」開啟網頁的速度挺沒效率的,很容易就超過預設的30秒。在整個測試正式開始之前,我先用setTimeout將逾時限制時間設定為60秒。由於setTimeout參數的單位是毫秒,60秒 x 1000 = 60000毫秒,所以輸入的參數是60000。
然後接下來就是正式開始測試了!
A1-1:開啟指定頁面
- Commend: open
- Target: http://pulipuli.blogspot.com/2011/06/blogger-image-lazy-load.html
- Value:
open(url)
參數:
- url - 要開啟的網址,可以是絕對網址或相對網址(相對網址是相對於Base URL的設定)。
使用open指令就能開啟指定頁面,用法簡單易懂。開啟之後的網頁如下:

等待網頁開啟完成之後,就會進入下一個指令。
A1-2:等待圖片延緩載入初始化
由於我在Blog中用了一些AJAX技巧,讀完網頁之後,還需要一段時間才會載入其他的功能,所以我需要知道圖片延緩載入初始化完成的時間。
圖片延緩載入的初始化特徵是會在圖片<img>標籤加上original屬性,用於記錄原本圖片的src網址。因此我們可以藉由偵測此屬性出現的時間,得知圖片延緩載入初始化完成。
同樣的,因為這是需要等待的測試指令,在此我使用waitForElementPresent:
- Commend: waitForElementPresent
- Target: css=img[title="2011-06-25_233326 設計 網頁元素"][original="http://lh4.ggpht.com/-a6cwLWbFve8/Tgg8J05sfPI/AAAAAAAAIYE/lU7sCSU6L0o/Image.png"]
- Value:
waitForElementPresent(locator)
參數:
- locator - 元素定位器
回傳:
如果元素定位器存在,則會傳true;否則回傳false。
再複習一下元素定位器的用法:
- identify=id
- id=id
- name=name
- dom=javascriptExpression
- xpath=xpathExpression
- link=textPattern
- css=cssSelectorSyntax
在這個例子中,我想要找的是瀏覽畫面以外的一張圖片,他帶有title屬性、值為「2011-06-25_233326 設計 網頁元素」。看它是否有original元素出現。正確的圖片如下:
我參考CSS3選擇器的語法,制定元素選擇器的內容:
css=img[title="2011-06-25_233326 設計 網頁元素"][original=http://lh4.ggpht.com/-a6cwLWbFve8/Tgg8J05sfPI/AAAAAAAAIYE/lU7sCSU6L0o/Image.png]

你可以用Selenium IDE的Target旁邊的Find按鈕來確認元素定位器是否正確。Find按鈕會找尋頁面中你定位的元素,並讓捲軸跳到該處。如果找不到或是語法錯誤,則會顯示錯誤訊息。
等待orginal屬性出現之後,測試就會進入下一個指令。
A2-1:確認瀏覽範圍外的圖片沒有載入
知道圖片延緩載入功能初始化成功之後,接下來我們要確認瀏覽範圍外的圖片並沒有在src屬性中載入正確的網址。
- Commend: assertElementNotPresent
- Target: css=img[title="2011-06-25_233326 設計 網頁元素"][src="http://lh4.ggpht.com/-a6cwLWbFve8/Tgg8J05sfPI/AAAAAAAAIYE/lU7sCSU6L0o/Image.png"]
- Value:
assertElementNotPresent(locator)
參數
- locator - 元素定位器
回傳
如果元素定位器並不存在,則回傳true;如果存在,則回傳false。
注意到這邊是以否定情況來測試,而這次元素定位器中css選擇器的屬性是src,而不是前一個指令中的original。
預期src的值會被取代為圖片佔位器的圖片,而不是原本圖片的網址。測試通過的話則進入下一個指令,否則終止測試。
A3-1:觸發圖片延緩載入功能
觸發圖片延緩載入的條件是將瀏覽範圍移動到該圖片的位置。Selenium並沒有移動捲軸的指令,但是卻可用runScript指令執行JavaScript程式碼,來達到移動捲軸的效果。
- Commend: runScript
- Target: window.scrollTo(0, $("img[title='2011-06-25_233326 設計 網頁元素']").offset().top);
- Value:
runScript(script)
- 參數
- script - JavaScript程式碼
由於我的Blog中已經載入了jQuery框架,所以在這邊我直接用jQuery的offset()方法來取得圖片距離頁面頂部的位置。然後再用JavaScript既有的window.scrollTo(x, y)來指定瀏覽範圍的位置。
透過runScript指令,即使你可能還不熟Selenium所有的指令,但你可能已經可以開始用任何你熟知的JavaScript方法來操作頁面的功能了。
runScript指令實際上是在頁尾插入一段<script>標籤,以執行指令中的JavaScript程式碼。例如上述指令則會在頁面最後插入以下程式碼:
<script type="text/javascript">
window.scrollTo(0, $("img[title='2011-06-25_233326 設計 網頁元素']").offset().top);
</script>
但是Selenium並不能掌控JavaScript程式碼執行時發生的錯誤,runScript永遠都是正確執行,並直接進入下一個指令。
A3-2:確認圖片正常載入
當瀏覽畫面移到該圖片的位置時,圖片延緩載入功能應該要能順利運作,將該圖片的src屬性換回正確的網址,讓圖片順利載入正確的圖片。
上一個指令是移動瀏覽畫面,然後還要等待圖片延緩載入替換圖片的src屬性。儘管這是人類難以察覺的短暫間隔,但這仍是要等待一小段時間。因此在此我用的是waitForElementPresent指令來確認圖片是否有正常地載入。
- Commend: waitForElementPresent
- Target: css=img[title="2011-06-25_233326 設計 網頁元素"][src="http://lh4.ggpht.com/-a6cwLWbFve8/Tgg8J05sfPI/AAAAAAAAIYE/lU7sCSU6L0o/Image.png"]
- Value:
waitForElementPresent(locator)
參數:
- locator - 元素定位器
回傳:
如果元素存在,則回傳true;否則回傳false。
waitForElementPresent會等待30秒鐘(可由setTimeout指令來改變預設的逾時時間),檢查該元素是否存在。如果圖片延緩載入有順利運作,那麼title為「2011-06-25_233326 設計 網頁元素」的圖片,其src屬性應該順利成為「http://lh4.ggpht.com/-a6cwLWbFve8/Tgg8J05sfPI/AAAAAAAAIYE/lU7sCSU6L0o/Image.png」
當圖片延緩載入順利啟動之後,這個測試指令就會成功。
測試案例結束訊息
Selenium IDE在測試結束之後不太會有明顯的通知。跑過幾次之後,我覺得是應該在測試案例最後加上測試結束的訊息。
- Commend: echo
- Target: 圖片延緩載入測試完成
- Value:
echo(message)
參數:
- message - 要顯示的訊息。
echo的訊息會顯示在Selenium IDE下方的Log欄位,如下圖:

如果看到Log中有「圖片延緩載入測試完成」的訊息,那麼就表示這整個測試案例已經跑完了,可以來確認一下有沒有哪些指令發生了錯誤。
幫測試案例加上註解

最後,為了讓測試案例容易閱讀,我們可以插入註解(Insert New Comment)來分隔各個測試指令。

註解的內容寫在Commend欄位裡面,如上圖。註解純粹只是在撰寫時給自己看的,並不會在測試時執行任何動作,也不會在Log中出現。
至此,整個測試案例就大功告成了。
測試運作結果

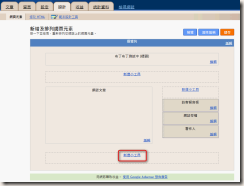
在Selenium IDE中按下「Play current test case」按鈕,就能夠執行目前選擇的測試案例,用以檢查剛剛建立的各種測試指令是否有如預期地運作。
檔案下載
Selenium IDE的測試案例(Test Case)跟測試組合(Test Suite)都是以HTML形式來儲存。

你也可以直接用瀏覽器來開啟,檢視測試案例的概要內容,如上圖所示。
運作影片
螢幕錄影是使用Cute Screen Recorder工具,這段影片沒有錄進聲音喔。
結語
這是我第一次製作Selenium測試案例。一開始草草上手,在寫這篇介紹的時候,又把測試案例的內容做過相當多修改。前前後後改了好幾次,也花了不少時間來寫,甚至比單純地學習如何操作Selenium IDE還要花上了更多時間。
如果有人發現我哪裡講錯了、或是前後不合的話,請務必告知指教。

題外話,在寫這篇的時候,WLW的排版也變得非常奇怪。左邊的邊界時常在變動,讓我挺擔心最後輸出時是否會有問題。總之,總算是寫完啦。
(more...)
2")












")























{kind=link}
Comments