[圖資]作業系統 922期中考 -2
[圖資]作業系統 922期中考 -2
九十二學年度第二學期
作業系統 期中考 之二
一、解釋名詞
1. Working set (工作集合)
工作集合(working set)是指在一定的時間中,某個行程(process)所參照(reference)到的分頁數量(pages),其時間同等於參照分頁的次數(a fixed number of page references)。假如在約5個參照分頁次數的時間中,該行程參照到了1 2 2 1 3這幾個分頁。那麼其工作集合為3個分頁,各別為1 2 3。
工作集合是用來預測該行程接下來要使用的需求欄位數量(demand frames),作業系統(OS)依照各個行程的工作集合來分配他們的欄位數量,以避免輾轉現象發生。
2. Thrashing (輾轉現象)
輾轉現象(thrashing)是指行程(process)分頁替換的頻率相當高,於是系統的時間相耗費在輸入輸出(I/O)的動作,CPU的使用率(utilization)低落,作業系統會認為需要增加多工的程度(the degree of multiprogramming),而又將行程加入系統中,每個行程所分配到的實體記憶體又更少,因而惡性循環。當各行程的總需求欄位空間(total demand frames)超過實體記憶體的欄位空間時,便會發生輾轉現象。
3. Dynamic linking (動態連結)
- 直到需要執行的時候,才會進行連結動作。當程式要用到系統程式庫(libraries)時,在需要參照(reference)的地方做記號(stub)
- 記號stub是用來找尋需要使用的程式庫(libraries),stup將會被取代為該程式庫的記憶體位置,並且執行該程式。作業系統需要確認該程式庫是否在實體記憶體當中。
- 有用到的程式資料庫在記憶體裡只會存在一份,而不必每次參照的時候都得複製,因此不會重複。鏈結(linking)的工作只需進行一次
- 動態連結特別適合程式庫(libraries)
二、試解釋內部斷裂(Internal fragmentation)與外部斷裂(external fragmentation)的差異。
- 斷裂(fragmentation)發生在行程(process)載入記憶體(memory)時,空間分配時發生的問題。
- 外部斷裂(external fragmentation)是指記憶體總和剩餘空間雖然足以載入整個行程,但因為剩餘空間被其他行程切割而不連續,所以無法載入行程,浪費記憶體空間。浪費的記憶體多寡,與記憶體選擇配置的演算法相關,也和記憶體空間總量以及行程的平均大小有關。
- 有時行程雖然小於記憶體某段連續的剩餘空間(坑洞),但在配置給該行程時,仍將整段空間都要走,以減少記憶體「小碎塊」的情況發生。這種行程額外要求了自己不需要的空間,稱之為內部斷裂(internal fragmentation)。
- 外部斷裂是指記憶體空間不連續,而無法配置給行程;內部斷裂是指被額外配置給行程,但實際並未被使用的記憶體空間。兩者相同的地方在於,都有不會被使用,而形同浪費的記憶體空間。
三、請略述處理分頁錯誤的步驟(最好畫圖表示,若以文字描述請將步驟標示清楚)
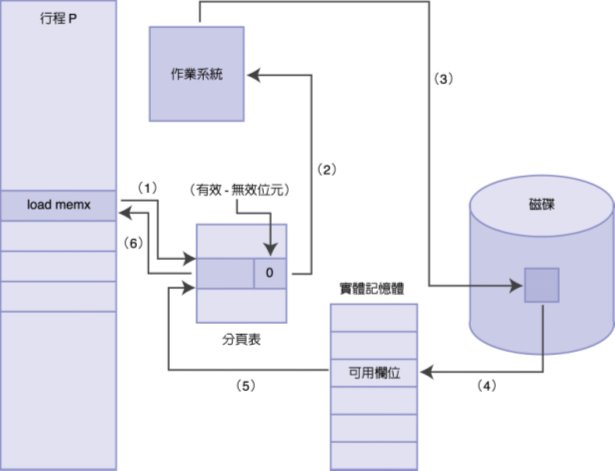
六個步驟
- 檢查TBL裡面需要的分頁的有效‧無效位元是否為1 (0代表尚未載入記憶體、1代表已經載入記憶體)→為0,發生分頁錯誤
- 發生分頁錯誤之後,暫停該行程的執行,進入監督模式,交由作業系統操作
- 作業系統到硬碟(second storage)去尋找程式(program,尚未在記憶體中執行的程式)所需的該段分頁
- 取出該分頁至實體記憶體的可用欄位。如果實體記憶體已經沒有可用欄位,則須先執行分頁替換的動作
- 所需分頁寫入實體記憶體之後,再修改分業表當中的有效‧無效位元,將它改成1(有效)
- 重新啟動行程,讓他再執行一次分頁要求,因為分頁已經載入,就不會發生分頁錯誤了
四、 以下列分頁參考串列為例︰
1,2,3,4,2,1,5,6,2,1,2,3,7,6,3,2,1,2,3,6
試問對下列分頁替換法而言,將分別產生多少次分頁錯誤?假設分配頁框數為4個頁框
1. LRU:共10次分頁錯誤
|
1 |
2 |
3 |
4 |
2 |
1 |
5 |
6 |
2 |
1 |
2 |
3 |
7 |
6 |
3 |
2 |
1 |
2 |
3 |
6 |
分頁表 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
6 |
6 |
6 |
6 |
6 |
6 |
6 |
|
2 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
|
|
|
3 |
3 |
3 |
3 |
5 |
5 |
5 |
5 |
5 |
3 |
3 |
3 |
3 |
3 |
3 |
3 |
3 |
3 |
|
|
|
|
4 |
4 |
4 |
4 |
6 |
6 |
6 |
6 |
6 |
7 |
7 |
7 |
7 |
1 |
1 |
1 |
1 |
|
未被使用時間 |
0 |
1 |
2 |
3 |
4 |
0 |
1 |
2 |
3 |
0 |
1 |
2 |
3 |
0 |
1 |
2 |
3 |
4 |
5 |
0 |
|
0 |
1 |
2 |
0 |
1 |
2 |
3 |
0 |
1 |
0 |
1 |
2 |
3 |
4 |
0 |
1 |
0 |
1 |
2 |
|
|
|
0 |
1 |
2 |
3 |
0 |
1 |
2 |
3 |
4 |
0 |
1 |
2 |
0 |
1 |
2 |
3 |
0 |
1 |
|
|
|
|
0 |
1 |
2 |
3 |
0 |
1 |
2 |
3 |
4 |
0 |
1 |
2 |
3 |
0 |
1 |
2 |
3 |
|
步驟
分頁錯誤,載入的分頁 (上一階段當中,未被使用時間最長的一個分頁)
檢查到已經有載入的分頁
|
||||||||||||||||||||
2. FIFO:共14次分頁錯誤
|
1 |
2 |
3 |
4 |
2 |
1 |
5 |
6 |
2 |
1 |
2 |
3 |
7 |
6 |
3 |
2 |
1 |
2 |
3 |
6 |
分頁表 |
1 |
1 |
1 |
1 |
1 |
1 |
5 |
5 |
5 |
5 |
5 |
3 |
3 |
3 |
3 |
3 |
1 |
1 |
1 |
1 |
|
2 |
2 |
2 |
2 |
2 |
2 |
6 |
6 |
6 |
6 |
6 |
7 |
7 |
7 |
7 |
7 |
7 |
3 |
3 |
|
|
|
3 |
3 |
3 |
3 |
3 |
3 |
2 |
2 |
2 |
2 |
2 |
6 |
6 |
6 |
6 |
6 |
6 |
6 |
|
|
|
|
4 |
4 |
4 |
4 |
4 |
4 |
1 |
1 |
1 |
1 |
1 |
1 |
2 |
2 |
2 |
2 |
2 |
|
載入時間 |
0 |
1 |
2 |
3 |
4 |
5 |
0 |
1 |
2 |
3 |
4 |
0 |
1 |
2 |
3 |
4 |
0 |
1 |
2 |
3 |
|
0 |
1 |
2 |
3 |
4 |
5 |
0 |
1 |
2 |
3 |
4 |
0 |
1 |
2 |
3 |
4 |
5 |
0 |
1 |
|
|
|
0 |
1 |
2 |
3 |
4 |
5 |
0 |
1 |
2 |
3 |
4 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
|
|
|
|
0 |
1 |
2 |
3 |
3 |
4 |
0 |
1 |
2 |
3 |
4 |
5 |
0 |
1 |
2 |
3 |
4 |
|
步驟
分頁錯誤,載入的分頁 (上一階段當中,載入時間最長的一個分頁)
檢查到已經有載入的分頁
|
||||||||||||||||||||
Second=Chance Algorithm:共10次分頁錯誤
|
1 |
2 |
3 |
4 |
2 |
1 |
5 |
6 |
2 |
1 |
2 |
3 |
7 |
6 |
3 |
2 |
1 |
2 |
3 |
6 |
分頁表 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
6 |
6 |
6 |
6 |
6 |
6 |
6 |
|
2 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
|
|
|
3 |
3 |
3 |
3 |
5 |
5 |
5 |
5 |
5 |
3 |
3 |
3 |
3 |
3 |
3 |
3 |
3 |
3 |
|
|
|
|
4 |
4 |
4 |
4 |
6 |
6 |
6 |
6 |
6 |
7 |
7 |
7 |
7 |
1 |
1 |
1 |
1 |
|
載入時間 |
0 |
1 |
2 |
3 |
4 |
5 |
0 |
1 |
2 |
3 |
4 |
0 |
1 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
|
0 |
1 |
2 |
3 |
4 |
0 |
1 |
2 |
3 |
4 |
0 |
1 |
2 |
3 |
4 |
0 |
1 |
2 |
3 |
|
|
|
0 |
1 |
2 |
3 |
0 |
1 |
2 |
3 |
4 |
0 |
1 |
2 |
3 |
4 |
0 |
1 |
2 |
3 |
|
|
|
|
0 |
1 |
2 |
3 |
0 |
1 |
2 |
3 |
4 |
0 |
1 |
2 |
3 |
0 |
1 |
2 |
3 |
|
參考位元 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
|
0 |
0 |
0 |
1 |
1 |
0 |
0 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
|
|
|
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
1 |
1 |
|
|
|
|
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
步驟
分頁錯誤,載入的分頁
檢查到已經有載入的分頁
受檢查,給予第二次機會的分頁
|
||||||||||||||||||||
五、略述記憶體管理中需求分頁(Demand Paging)的做法
- 需求分頁的基本道理是:「直到需要執行的時候,才將分頁載入記憶體」。
- 在分頁的作法中,程式(program,當程式在執行狀態的時候,稱為行程或程序(process))會被分割成大小相等的分頁,這時程式是被擺置在次儲存裝置(second storage),如硬碟當中。當程序(process)執行時遇到須要使用的部份分頁,才去載入分頁。
- 需求分頁使用了分頁表來記錄該分頁是否已經載入記憶體。分頁表基本上有三個欄位:分頁編號、分頁實體記憶體位置、分頁已載入的有效-無效位元(valid-invalid bit),其中有效-無效位元是用來紀錄分頁是否已經載入記憶體。如果未載入為0,表示該分頁上在磁碟當中;已經載入為1,表示已經存在於記憶體當中。
- 程序的需求分頁動作會先檢查分頁表的有效-無效位元,如果為1,則正常執行;如果為0,則發生分頁錯誤。分頁錯誤時的處理,可以參考第三題。
六、下列程式設計技巧和結構中,哪些對需求分頁的環境有利,哪些則相對的顯得不利?並請簡單敘述你的理由。
- 堆疊(stack)
- 循序搜尋法(sequence search)
- 純程式碼(pure code)
- 向量運算(vector operations)
- 間接定址(indirection)
首先,需求分頁的特色在於將程序執行時所需要的記憶體空間降至最低,因為只載入需要的分頁。但是當記憶體空間不足時,則需要執行花費時間的分頁替換動作(page replacement)。減少分頁替換的情況發生,也就是程序執行時,重覆使用同一個分頁;其次是按照順序地執行分頁,這些都是有利於需求分頁環境的結構。相對的,不按照順序、跳來跳去的程式結構,將會時常需要載入位置差異大的分頁,而不利於需求分頁的環境。
- 堆疊(stack):堆疊是一種先進後出的資料結構。例如有A B C D這四個資料依順序進入堆疊,則接下來出來的則是D C B A。從執行順序來看,會變成A B C D D C B A。其中存取A的兩個時間差距遠,表示時常要載入位置差異大的分頁,因此不利於需求分頁的環境。
- 循序搜尋法 (sequence search):這是一種用於搜尋的演算法。例如要在A B C D當中檢查D的位置,則程式會從A B C D一個一個依序地檢查。其使用的分頁是有順序性的,因此利於需求分頁環境。
- 純程式碼 (pure code):程式碼不可被其他程式修改,而用來重複執行的程式碼稱之,又稱為共同程式碼。因為該段程式碼(等於分頁)重複使用,因此有利於需求分頁環境。
- 向量運算 (vector operations):向量是指具有方向的量單位,如往北走20公里,此為向量的表示。在電腦運算中,單向、平面或立體圖形的向量通常用一維、二維或三維矩陣表示,而向量的運算便是矩陣之間的運算。程式中常使用陣列的方式來表示矩陣,而程式語言對陣列的Column-major(欄優先)還是Row-major(列優先)分配分頁的方式,與程式中先執行列還是執行欄的差別,便會影響到分頁錯誤的發生頻率。當分配分頁方式與執行順序相同時,會利於需求分頁的環境;反之,則是不利於需求分頁。







{kind=link}
Comments