A Knowledge Network Constructed by Integrating Classification,Thesaurus, and Metadata in Digital Library
書目資料:
- 篇名:A Knowledge Network Constructed by Integrating Classification,Thesaurus, and Metadata in Digital Library
- 作者:JUN WANG
- Intl. Inform.&Libr. Rev. (2003), 35, 383~397
摘要
現今檢索系統最常使用的技術是關鍵字檢索(keyword-based search),然而這種方式卻忽略了詮釋資料(metadata,因為習慣所致,接下來我都會寫成metadata)的價值。該文將結合分類法(classification)以及索引典(thesaurus)而成為一種概念網路(concept network),然後將metadata記錄依照主題(subject)排列。
該文並建置了一個系統VISION用來驗證其理論,這是結合了漢語分類主題一體化詞表(Chinese Classification and Thesaurus)與北京大學圖書館的書目資料計算而成的結果。
這種概念網路不僅只是metadata的組織框架,同時也是一種知識導覽、檢索、以及學習的結構,而作者相信它將會把數位圖書館提升成為知識管理中心。
好啦,反正這種自動產生概念網路的論文很多,好處跟優點大家都差不多。所以要看這種論文,重點要擺在理論與實驗驗證的部份,該文的實驗部分僅有系統介紹,並沒有證實用的測試數據,故以下僅談理論部份。
知識網路整合分類法、索引典以及詮釋資料 Knowledge Network Integrating the Classification, Thesaurus, and Metadata (KNICTM)
這方法是把分類法與索引典當成是組織書目資料的骨架,而書目資料則是框架的內容。在這種作法中,藉由從書目資料自動地抽取出新的辭彙,可用於更新分類法與索引典,以構成知識群組。最後分類法與索引典也會符合專屬領域的OPAC資源(Open Public Access Catalog,開放線上目錄,就是圖書館網站裡面最重要的那個查詢系統啦)。
KNICTM的作法有三個步驟,整個過程最後將會產生出一棵樹(tree)。這步驟簡單來說各別是創造骨架、充實內容、新增內容:
1. 以分類法與索引典為基礎,建構原始的概念節點(concept node)
首先,要將索引典轉換成原始的概念網路,它包括了節點(nodes)與邊(edges)。
每個節點都是一群同樣意思的主題詞,包括了索引典中所有相關的詞彙。如果兩個主題詞之間有層級的關係,這兩個節點則連上「is-a」的邊,表示兩者之間有所關聯。is-a白話就是「是一個」,例如「正方形」「是一個」「長方形」,大概是這種感覺。
如此不斷重複的訓練過程,就能夠將分類法嵌入概念網路中。這個概念網路你可以想像成一個骨架,能夠呈現出分類法與索引典的骨架。
2. 將書目資料加入概念網路中
將相關的書目資料結合之後,摘要概念節點(abstract concept node)將可以成為知識節點,而概念網路(concept)將轉變成實體的知識網路(knowledge)。從這邊你可以稍微理解概念網路與知識網路的差別了,一個只是架構,另一個則是有東西在裡面。
將書目資料記錄(bibliographic data records,BDR)結合到概念網路的方法如下:
如果BDR只有一個主題詞,那麼就直接找到相關的概念節點,並把該BDR加進去。如果BDR包含了許多的主題詞,那麼就照上面的作法一一將主題詞加入,很廢話。
重點在於,如果BDR中有多個主題詞組成的混合主題詞(composite subject)時,就要創造一個新的概念節點,然後將它與其他偶關聯的節點連上「related-to(關聯到)」的邊。這個新的節點稱為「co-concept(聯合概念)」節點,該節點只有BDR並且此時沒有主題詞(因為不是由第一步的分類法與索引典而來的)。
例如BDR有個主題詞叫做「Internet Firewall Technologies(網際網路防火牆技術)」,它與「Network-Security(網路保全)」有關,但是在索引典裡面並沒有「firewall(防火牆)」這個詞。現在就要建立一個co-concept節點,然後用relate-to把它跟Network與Security節點連起來,而這個包含BDR的co-concept節點就是關聯的驗證。
在下一步當中,要把新抽取出來的詞彙加入co-concept當中,在此例裡面就是將「firewall」加入。
KNICTM需要經常手動(?)檢查確認co-concept是否正常建立。當更好的詞彙可以代表的這個co-concept的時候,該節點將會轉換成通用概念節點(common concept nocde)。你可以想像成原本的節點達到足夠重要的條件,所以將它升級的意思。只是為何要用手動檢查呢?
3. 加強KNICTM
這是最後也是最困難的工作,現在要從metadata集合當中找出新的辭彙,以加強KNICTM。
一般來說,科學性的文獻通常可以從標題去抽取出關鍵字,以找到相對應的主題詞。從語意上去對照,即可找出新的辭彙,並且將它加入概念網路中。
這邊有三個困難之處需要克服的:
- 標題中如何分辨重要與不重要的辭彙?
- 該怎麼決定抽出來的詞彙要不要加入到KNICTM?
- 中文斷詞,這是中文檢索永遠的問題
最後KNICTM將會長得像一棵樹。我覺得作者在此時應該放張圖片來說明,這樣應該會更好懂,所以我決定畫張圖來說明吧!
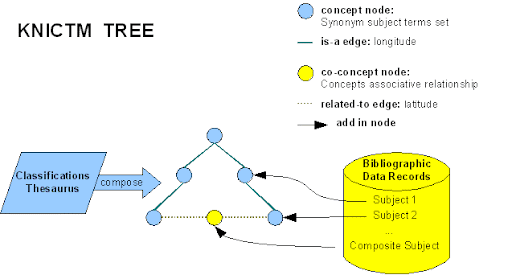
這張圖有簡化過概念,我覺得這樣應該會比作者的敘述更好理解。想要實作的話就再繼續細讀這篇後面的實驗部份吧!
剩下的篇幅,作者都在介紹他的VISION實驗系統。只是單純介紹系統的話,我覺得那是要等實作的時候再去觀摩就好。
本來很想知道到底KNICTM的演算法能作到什麼程度,作者要用什麼方式去驗證,或是比較KNICTM與其他的concept network的優劣,可惜都沒有這方面的資料。
故本篇閱讀心得也到此為止,感謝大家收看。

{kind=link}