簡單易用的中英文斷詞和詞性標註:Python-Jieba / Word Segmentation and Part of Speech Anlysis: Python-Jieba

要對非結構化的文字資料進行分析,第一件事情是對文字資料抽取結構化的量化數值特徵。除了用「文字探勘分析器」簡單分析字數、句數之外,最常見的分析方式就是斷詞和詞性分析,例如線上中文斷詞工具:Jieba-JS。但Jieba-JS並不能發揮Jieba斷詞器的全部功能,所以我以Python撰寫了簡單易用的斷詞和詞性分析工具Python-Jieba,讓大家不用撰寫程式碼,只要簡單的配置,就能進行中文斷詞和詞性分析,還能夠同時分析中英混雜文本中英文的詞性。
Python-Jieba不只可搭配「非結構化資料分析:文本分類」或「Weka的中文自動評分」等機器學習來使用,更可以用在質性研究的內容分析、文本分析或敘說分析上,先用Python-Jieba找出特定詞性的文本內容來分析。
下載與配置 / Download

- GitHub: Python-Jieba
- ZIP壓縮檔案下載 (壓縮檔有17.7MB左右,解壓縮後有56.2MB)
- Python 2下載
Python-Jieba是以Python 2.7.13環境下寫成的程式,中文的斷詞與詞性標註核心套件是Jieba的Python版本,英文的詞性標註是用pyPartOfSpeech套件。這兩個套件分析出來的詞性標記,請看「彙整中文與英文的詞性標註代號:結巴斷詞器與FastTag」這篇的說明。此外,為了讀取ini和csv格式的檔案,執行時還需要安裝一些其他套件,這些都寫在install_packages.py之中,第一次執行主程式時會逐一檢查並自動安裝。
要使用Python-Jieba的話,請直接下載ZIP壓縮檔,解壓縮到任何位置即可。關於ZIP解壓縮的部分,可以參考「你還在用WinRAR壓縮嗎?是該改用ZIP格式來壓縮了」這篇。
檔案配置 / File stucture

Python-Jieba主要有3個需要注意的資料夾。config裡面擺放各種設定檔,input擺放需要作斷詞和詞性分析的文本檔案,output則擺放對應於input的執行結果。後面操作說明時會再介紹這些資料夾裡面的檔案。run_jieba.py是主要執行程式。在Windows環境下,可以直接執行run_jieba_cli.bat即可。
Python第二版 / Python 2

必須說明的是,我在開發時是以Python 2.7.13為主,也就是Python第二版。Python第二版跟現今主流的Python第三版有不少的差別,特別可以使用的套件相容性問題。因此不同版本執行的時候可能會有問題。這邊我只有試過使用Python 2來運作,如果你的Python 3不能跑,那請試著換一成Python 2看看。現在最新的Python 2是Python 2.7.15。
編輯器 / Editor
純文字編輯器:Notepad++ / Plain Text Editor: Notepad++

- Notepad++官方網站:https://notepad-plus-plus.org/
- Notepad++安裝版下載網頁:https://notepad-plus-plus.org/download/v7.2.2.html
-
Notepad++可攜版 Notepad++ zip package 32-bit x86 檔案備份:Google Drive、OneDrive、Box、Mega、MediaFire
Python-Jieba的所有檔案都是以UTF8編碼的純文字檔案。操作時雖然不需要寫程式,但是還是需要調整設定檔。我建議大家使用Notepad++等純文字編輯器來修改這些設定檔。我現在使用的Notepad++是7.2.2版本。
CSV檔案編輯器:LibreOffice Calc / CSV Editor: LibreOffice Calc

- LibreOffice Portable: http://portableapps.com/apps/office/libreoffice_portable
- LibreOffice Portable 5.1.1 (All Languages) Google Drive備份
Python-Jieba大部分的設定檔都是以CSV逗號分隔值形式儲存的檔案。要編輯CSV檔案,我推薦使用LibreOffice Calc,因為它能夠正確的識別UTF編碼的CSV檔案。

注意不要用Microsoft Office的Excel,因為它預設是以Big5編碼來開啟CSV,這會導致檔案開啟後變成亂碼。
操作說明 / Instruction
Python-Jieba的操作不寫程式,而是直接在檔案管理中在input資料夾放入要處理的檔案、在config資料夾裡調整設定檔、執行指令run_jieba_cli.bat,就能在output資料夾取得分析結果。以下就請跟著操作看看吧。
1. 輸入檔案 / Input

輸入檔案接受兩種格式:副檔名為txt的純文字檔案,以及副檔名為csv的逗號分隔值。兩者都必須以UTF8編碼儲存。如果你不確定是不是UTF-8格式,請參考「如何把純文字檔案轉換成UTF-8格式:使用Notepad++」這篇。
我在範例中放入了三個檔案,包括兩個txt副檔名的純文字檔案,跟一個csv副檔名的逗號分隔值。以下是這兩種輸入檔案格式。
純文字檔案 (*.txt) / Plain text (*.txt)


純文字檔案裡面就只是單純的純文字,換行會被替換成空格後,再來進行斷詞和詞性分析。你可以用Notepad++來編輯這個純文字檔案。
逗號分隔值 (*.csv) / Comma-Separated Values (*.csv)

逗號分隔值第一列必須是欄位名稱,第二列之後才是資料。Python-Jieba會將每一列中的每一欄視為一份純文字檔案文本,各別進行斷詞和詞性分析。你可以用LibreOffice Calc來編輯這個逗號分隔值CSV檔案。
2. 設定檔案 / Configuration

設定檔都放置在config資料夾中,以下我們就來看看有那些可以設定的吧。
主要設定檔 config.ini

config.ini是主要的設定檔,裡面重要設定的內容如下:
- mode=mix:斷詞模式,預設採用混合,可以綜合原本Jieba的exact精確模式、all全模式、search搜尋引擎模式的所有斷詞結果。
- separator=:斷詞結果分隔符號,預設是空格。
- export_text_feature=true:是否顯示字數、斷詞數、entropy等額外的量化分析
- enable_pos_tag=true:是否進行詞性分析
- add_pos_field=true:是否將詞性獨立於額外欄位
其他設定大多都是固定的欄位,不需修改。
使用者詞表 user_dict.csv

使用者詞表 user_dict.csv 包含了二個欄位:word 詞跟pos 詞性標示。Jieba的使用者詞表還會要求加上權重,在這裡我預設使用99999的極大數字作為權重,以確保這個詞能夠被優先斷出。你也可以將英文單字加入在這個使用者詞表中,Python-Jieba會優先將此單字標示為特定詞性。
必須注意的是,Python-Jieba裡面使用詞性標註的方式是以詞表為主,並不會根據上下文來推斷。因此請務必要將專有名詞的詞性設定在此表中。Jieba的詞性分析主要從既有的使用者詞表中找出詞彙和對應的詞性。如果是未知詞,則拆解該詞為多個詞,從中根據已知詞性和位置來估算該未知詞的可能詞性。細節請看「jieba 词性标注是怎么实现的?」這篇。如果文本中包含大量未知詞,那對於詞性分析的結果就需要謹慎的評估。
附帶一提,正體中文跟簡體中文被視為不同文字,它們之間不會自動轉換。
對應詞表 map_word.csv

對應詞表 map_word.csv 包含兩個欄位:word 詞、map_to 對應詞。在分析開始之前,Python-Jieba就會根據對應詞表將原本文字中詞換成對應詞。這個動作優先於任何分析。注意,正體中文跟簡體中文之間不會自動轉換,它們被視為是不同的文字。
對應詞性表 map_pos.csv

跟對應詞表很像的是另一個對應詞性表 map_pos.csv。對應詞性表也包含兩個欄位:pos 詞性、map_to 對應詞性。詞性分析的結果會依照對應詞性表自動轉換,例如將「eng-VB」轉換為「v」,這樣可以合併類似的詞性,以便後續的分析。值得注意的是,因為中文詞性標註是用Jieba,英文詞性標註是用pyPartOfSpeech,兩個套件使用的詞性標註結果各別分開,英文的部分開頭會有「eng-」,因此你可能會需要搭配對應詞性表 map_pos.csv來合併詞性。
map_pos.csv中已經將大部分詞性對應到14種主要詞性。這個對應詞性表是參考了「彙整中文與英文的詞性標註代號:結巴斷詞器與FastTag」這篇,各種詞性表對應的14種主要詞性如下:
- POS-adj 形容詞
- POS-adv 副詞
- POS-conj 連接詞
- POS-int 感嘆詞
- POS-m 數詞 (結巴獨有)
- POS-n 名詞
- POS-o 擬聲詞
- POS-prep 介系詞,介詞
- POS-pron 代詞,代名詞
- POS-punc 標點符號
- POS-q 量詞
- POS-u 助詞,結巴獨有
- POS-unknown 未知詞
- POS-v 動詞
停用詞表 stop_words.txt

停用詞表 stop_words.txt 可以設定不想要出現在分析結果的停用詞性,例如一些常用詞或是虛詞,像是「我」、「吧」,一行一個詞。

我另外將常見的停用字製作了stop_words_sample.txt。這是我參考了林宏仁的 機器學習 筆記中的「停用詞-繁體中文.txt」跟「停用詞.txt」,將正體中文和簡體中文合併而成的檔案。這個stop_words_sample.txt會過濾掉許多文字,我預設並不採用,你可以自行決定是不是要用這個停用詞表。
停用詞性表 stop_pos_tags.txt

停用詞性表 stop_pos_tags.txt 可以設定不想要出現在分析結果的特定停用詞性,例如像是表示副詞的「POS-adv」或是標點符號的「POS-punc」,一行一個詞性。

有些時候我們的分析只想留下名詞,那就可以套用only-pos-n裡面的stop_pos_tags.txt。這個設定裡面排除了POS-n名詞之外的所有詞性,因此最後只會找出名詞。
3. 執行分析 / Run Jieba

Windows使用者的話,請點選「run_jieba_cli.bat」檔案即可執行。其他平台則可以用以下指令來執行:
python run_jieba.py4. 輸出檔案 / Output

如果輸入檔案是純文字的txt檔,則會變成具有多個欄位的逗點分隔值csv檔案。csv檔案則會根據原本的欄位名詞增加更多分析結果的額外欄位。讓我們來看看分析結果吧。
純文字檔案的分析結果 / Result from plain text

在預設的設定中,純文字檔案分析結果分成了7個欄位:
- seg:斷詞結果,例如:「我 學 大 治 政 區 到 來 來到 文山 區政治 大學 take a test ! 我 來到 文山 區政治 大學 take a test !」
- pos:斷詞對應的詞性,例如:「POS-pron POS-adv POS-adj POS-v POS-n POS-n POS-v POS-adv POS-v POS-n POS-n POS-n POS-v POS-adv POS-n POS-punc POS-pron POS-v POS-n POS-n POS-n POS-v POS-adv POS-n POS-punc」
- text_len:原始文本的字數 (換行跟空格皆被視為一個字),例如:「45」
- seg_count:斷詞結果不重複的數量,例如:「25」
- pos_count:詞性不重複的數量,例如:「6」
- seg_entropy_count:斷詞結果的亂度,亂度越高表示使用的詞彙越多元,例如:「2.71980985487」。0就是只有出現一個詞,關於entropy的介紹和算法,請看「文字探勘分析器」這篇。
- pos_entropy_count:詞性的亂度,亂度越高表示使用的詞性越多元。例如:「1.53510886839」。
為何輸入的時候是「我來到大安區臺灣大學take a test!」,但輸出的斷詞卻是「我 學 大 治 政 區 到 來 來到 文山 區政治 大學 take a test !」呢,這是因為我在前面的對應詞表 map_word.csv設定中,將「大安」換成「文山」、「臺灣」換成「政治」,所以最後斷詞結果就已經是替代的結果了。
逗號分隔值的分析結果 / Result from CSV

CSV的分析結果跟純文字檔案分析結果很類似,只是欄位名稱會以原本CSV欄位名稱為開頭再額外新增其他的分析結果欄位。
斷詞、詞性與文字探勘分析器的整合應用 / Integrate Python-Jieba into Text Analyzer

Python-Jieba的分析結果能夠跟我之前作的文字探勘分析器整合。以下我們以107年國慶大會總統致詞作為輸入文本來操作看看。


我使用only-pos-n中的設定,停用名詞之外的詞性,斷詞模式設為精確mode=exact,這樣子可以取得文本中的名詞。

然後再把seg斷詞結果丟到文字探勘分析器中,將Segment Type斷詞類型改為「Space」空格,調整文字雲的Weight Factor為10,再按下「START」進行分析。

最後就能夠得到一張文字雲,可以很快地看到文本中常被提及的名詞為何。

也可以從「Words Distribution」中取得出現頻率的統計表格。
文本分類的整合應用 / Integrate Python-Jieba into Text Classification

Python-Jieba的分析結果還能夠強化文本分類的預測正確率。在「非結構化資料分析:文本分類」課程中,以是籃球還是地球?的資料集為例子來做文字分類時,因為使用的是簡單的Jieba-JS,所以斷詞結果並不是非常全面。我們現在有了Python-Jieba,可以用混合模式提取更多斷詞結果,那我們就用是籃球還是地球?資料集再來跑一次。


先將資料集中的document進行Python-Jieba的斷詞和詞性分析處理,這邊用的設定檔是沒有停用詞和停用詞性的text-mining,斷詞模式設為混合mode=mix。最後我們就能得到7個欄位,例如第一份斷詞,以此作為文本的特徵。
從這裡我們可以比較一下Jieba-JS跟Python-Jieba的處理結果差異。Jieba-JS的斷詞結果是「奧運會 籃球比賽 和 世界 籃球 錦標賽 的 比賽場地 長度 是 28 公尺 寬 15 公尺」,取得了15個詞,其中「籃球比賽」跟「籃球」被斷成了不同的詞彙。Python-Jieba的斷詞結果是「奧運 奧 運 度 長 場 賽 標 錦 球 籃 界 世 會 籃球 比賽 和 世界 籃球 錦標賽 的 比 賽場 地 長度 是 28 公尺 公 尺 寬 15 公尺」,共取得33個詞,而且籃球比賽也被斷成了「籃球」。不過Python-Jieba卻沒有斷出「籃球比賽」,可能是Jieba詞庫設定不同的關係吧,詳細可以參考「如何使用 jieba 結巴中文分詞程式」這篇。

在試算表轉ARFF中,「String類型欄位使用斷詞」選擇「以空格隔開的單字」,這時候我們不用再做「jieba斷詞」。

後續的分析方式跟「Part 3. 實作:文本分類」一樣,請照著投影片來作就可以了。在以訓練集建立模型時,Correctly Classified Instances 正確率為90% ,比當初用Jieba-JS去做建模時的80%還要更高。
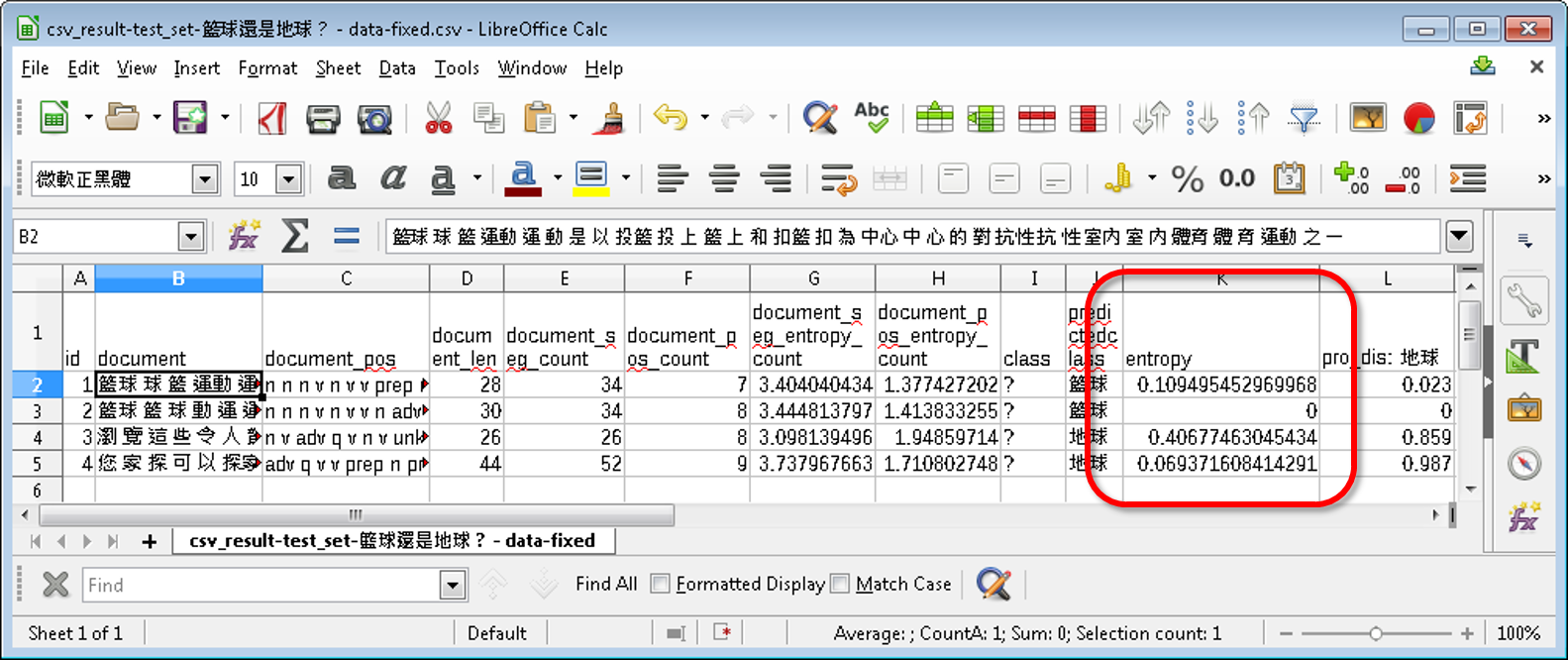
經過Python-Jieba處理後,最後得到的預測結果不僅正確,而且預測結果的entropy都比Jieba-JS得到的結果還要低,也就是預測結果更加確定、也更為可靠的意思。
以id 1的第一筆資料來說,Jieba-JS斷詞處理後的entropy為0.57,而現在使用Python-Jieba處理後的結果降到了0.11。由此可知,只要有更多的文字特徵,便能大幅提升文本分類的效率。
結語 / In closing
Python-Jieba是為了那些不會寫程式、但是又需要作文本分析的人而開發的工具。雖然斷詞跟詞性標註的套件很多,但對於大部分的人來說,都只是看得到吃不到,沒辦法好好活用這些工具。
Python-Jieba在原本Jieba之上,又做了大量的包裝。原本的Jieba詞性標註與斷詞是兩個額外的功能,兩者不能同時使用。在Python-Jieba中,我先用Jieba的斷詞,再將斷詞結果丟入Jieba的詞性分析,以此整合斷詞和詞性標註的結果。而Jieba預設並不會標註英文的詞性,因此英文詞性標註的部分則使用pyPartOfSpeech套件。此外,Jieba跟pyPartOfSpeech兩者都不會處理大部分標點符號的詞性標註,因此我又用使用者詞表 user_dict.csv 來解決這個問題。
在做了上述的處理後,Python-Jieba就成了可以為中文和英文混雜的文本進行斷詞、詞性標示的分析,而且分析所需要的設定和詞表都獨立成各別檔案,方便編輯和修改。
學術界常常會有質性研究和量化研究之爭,而質性研究大多人都是採用內容分析、文本分析或是敘說分析。這些分析需要處理的文字量相當大,需要研究者一字一句仔細閱讀於分析。不過,如果有Python-Jieba的話,其實可以先試著將這些文字丟進來作斷詞與詞性分析。在對應詞性表 map_pos.csv與停用詞性表 stop_pos_tags.txt中設定僅保留未知詞和名詞的話,也許就能快速找到文本中有趣的關鍵字。
當然,我並不認為斷詞和詞性分析能夠就是文本分析的全部,這樣子看待質性研究也過於膚淺。不過像是Python-Jieba這樣能讓研究者在短時間內就可以獲得一些分析結果,把這種方法當作一個起點,試試看又有何不妨呢?
最後來講一下開發Python-Jieba的一些其他想法。開發Python-Jieba是在2018年年中的時候,那時候很多學弟妹的論文都需要用到內容分析,不過可惜的是最後並沒有人真的認真去實作,所以我決定自己來把它做成一套工具供大家使用。製作的時候繼承了循序樣式探勘:以Python的PrefixSpan實作的做法,以設定檔和輸入檔案的形式來做成工具。但在這次做完Python-Jieba之後,我開始覺得這個方法並不是很方便。而且雖然Python是很好寫沒錯啦,但它總是在編碼或一些小地方讓我覺得卡卡的。後來我整理了「混合應用程式框架」之後,我想未來應該會更加偏向使用Node.js來做這些應用,寫起來會更加得心應手吧。
那麼這次對於Python-Jieba的介紹就到這裡了。你的文字探勘或文本分析都是怎麼做的呢?你知道斷詞跟詞性標註嗎?你有過使用這些技術解決問題的經驗嗎?你覺得Python-Jieba能夠對你有什麼幫助嗎?歡迎在下面的留言處跟我們分享你的想法。如果你覺得我這篇教學寫的不錯的話,請幫我在AddThis分享工具按讚、將這篇分享到Facebook等社群媒體吧!感謝你的耐心閱讀,讓我們下一篇見。

{kind=link}
作者已經移除這則留言。
回覆刪除最近有網友需要使用這個工具。
回覆刪除有鑑於此工具是用老舊的Python 2撰寫,而且許多套件已經不存在pip中。
我試著把它重新以docker包裝。
----
現在這個套件的安裝方法如下:
1. 安裝git指令
https://github.com/git-guides/install-git
2. 複製Git保存庫到本機端
git clone https://github.com/pulipulichen/Python-Jieba.git
3. 移動到目錄底下
cd Python-Jieba
4. 安裝Docker-compose指令
https://docs.docker.com/compose/install/
5. 執行指令
docker-compose build
----
使用方法如下:
1. 把你要處理的檔案放到 `input` 目錄。
2. 移動到目錄底下:
cd Python-Jieba
3. 執行指令:
docker-compose up
4. 在 `output` 目錄取得結果。
這樣就可以了。
你完全不用管你電腦裝的Python是什麼版本,反正都包在Docker裡面了。