[圖資]作業系統 922期中考 -1
[圖資]作業系統 922期中考 -1
九十二學年度第二學期
作業系統 期中考 之一
一、解釋名詞
1. 布雷第異常現象(Belady’s anomaly)
一般來說,在同一種分頁替換演算法當中,將記憶體容量增加以增加分頁可用欄位的時候,應該會減少分頁錯誤的次數;可是有時因為可用欄位的增加而降低了CPU的使用率,OS因而加入了更多分頁,導致可用欄位相對不足,分頁錯誤便沒有減少。這種違反一般趨勢的現象,即稱為布雷第異常現象。
2. 純程式碼(pure code)
純程式碼又稱為共同程式碼,他是一種不會被改變、可以重複使用的程式碼。一般是用於程式庫(libraries)等常被參照(reference)的用途。
3. 工作集(working set)
工作集合(working set)是指在一定的時間中,某個行程(process)所參照(reference)到的分頁數量(pages),其時間同等於參照分頁的次數(a fixed number of page references)。假如在約5個參照分頁次數的時間中,該行程參照到了1 2 2 1 3這幾個分頁。那麼其工作集合為3個分頁,各別為1 2 3。
工作集合是用來預測該行程接下來要使用的需求欄位數量(demand frames),作業系統(OS)依照各個行程的工作集合來分配他們的欄位數量,以避免輾轉現象發生。
4. 何謂分頁錯誤(page fault)?
記憶體分配中,使用分頁式將行程拆成數個行程,然後一個個分頁接著執行,需要存取到還沒有載入記憶體的分頁而發生錯誤,而這種狀況即稱為分頁錯誤。
二、
1. 請略述處理分頁錯誤發生與處理的過程(最好畫圖表示,若以文字描述請將步驟標示清楚)
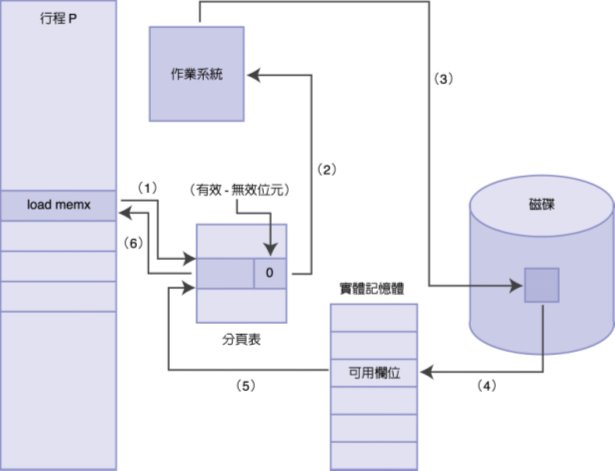
- 檢查TBL裡面需要的分頁的有效‧無效位元是否為1 (0代表尚未載入記憶體、1代表已經載入記憶體)→為0,發生分頁錯誤
- 發生分頁錯誤之後,暫停該行程的執行,進入監督模式,交由作業系統操作
- 作業系統到硬碟(second storage)去尋找程式(program,尚未在記憶體中執行的程式)所需的該段分頁
- 取出該分頁至實體記憶體的可用欄位。如果實體記憶體已經沒有可用欄位,則須先執行分頁替換的動作
- 所需分頁寫入實體記憶體之後,再修改分業表當中的有效‧無效位元,將它改成1(有效)
- 重新啟動行程,讓他再執行一次分頁要求,因為分頁已經載入,就不會發生分頁錯誤了
2. 試討論在需求分頁記憶體管理方法中,分頁大小的優劣。
分頁(page)越小的情況下,將可以越精確地填滿記憶體空間,而不會有浪費的空間。對於需求分頁的記憶體管理方法來說,分頁越小越好。但由於分頁縮小相對於程式碼也不多,執行時將會時常參照(reference)到其他分頁,因此分頁錯誤(page fault)的次數也會相對增加。分頁錯誤所需耗掉的輸入輸出(Input / Output,I/O)時間往往是最耗時的動作,比較起來,內部斷裂(internal fragmentation)相對的較省時。因此虛擬記憶體仍傾向使用大的分頁。
三、請說明在分頁法中為何要使用翻譯側看暫存區(translation look-aside buffer, TLB)這樣的硬體機制?
- TLB(翻譯成「旁邊找尋轉移暫存區」會比較好)是為了解決兩個記憶體使用程式而發展出來的特殊高速搜尋的硬體快取裝置,又稱為組合記憶體(associative memory)。
- TLB分成兩個欄位:分頁編號(page number)與頁框編號(frame number),個別紀錄程式的邏輯位置(logical address)與實體記憶體位置(physical address)。
- 當程序需要參照某個分頁時,會先到TLB去找尋該分頁的頁框位置,如果找不到,才到分頁表(page table)裡去尋找。如下圖:

四、
1. 略述記憶體管理中分頁法(paging)和分段法(Segmentation)的差異?
分頁法是將程式分割成固定大小的分頁,但是各分頁並沒有邏輯性,如果要執行程式中一個常被用到的部份,他可能會被分割在數個不同的分頁當中。
而分段法則是以邏輯性的完整性為出發點,程式依照邏輯性來分割,因此各個部份大小會不相同。
分頁法因為分頁大小相同而可以解決外部斷裂的問題,分段法因為大小不同而不行。
2. 並請就內部斷裂(Internal fragmentation)與外部斷裂(external fragmentation)的產生情形進行說明與討論。
- 外部斷裂(external fragmentation)是指記憶體總和剩餘空間雖然足以載入整個行程,但因為剩餘空間被其他行程切割而不連續,所以無法載入行程,浪費記憶體空間。浪費的記憶體多寡,與記憶體選擇配置的演算法相關,也和記憶體空間總量以及行程的平均大小有關。
- 有時行程雖然小於記憶體某段連續的剩餘空間(坑洞),但在配置給該行程時,仍將整段空間都要走,以減少記憶體「小碎塊」的情況發生。這種行程額外要求了自己不需要的空間,稱之為內部斷裂(internal fragmentation)。
- 外部斷裂是指記憶體空間不連續,而無法配置給行程;內部斷裂是指被額外配置給行程,但實際並未被使用的記憶體空間。兩者相同的地方在於,都有不會被使用,而形同浪費的記憶體空間。
五、試問下列兩個程式在需求分頁(分頁大小64個word)的記憶體管理策略下,有何不同或影響?
P1:
for (i=0;i<64;i++ ){ for(j=0;j<64;j++){ A[i][j]=0; } } |
P2: for (j=0;j<64;i++ ){ for(i=0;i<64;j++){ A[i][j]=0; } } |
比較這兩者程式使用的資料順序: |
|
P1: A[0][1] A[0][2] … A[0][63] A[1][0] … A[63][62] A[63][63] |
P: A[2][0] … A[63][0] A[0][1] A[1][1] … A[62][63] A[63][63] |
由此可知,P1使用到j(欄)的頻率高,而P2使用到i(列)的頻率高。在記憶體管理策略當中,如果是column-major(欄為主),則P1的情況下發生分頁錯誤的情況會比較少,因為分頁都在附近;反之,如果是row-major(列為主)的情況下,較適合P2
六、以下列分頁參考串列為例︰
1,3,2,4,2,1,4,6,2,1,4,3,7,6,3,2,1,2,3,6
試問對下列分頁替換法而言,將分別產生多少次分頁錯誤?假設分配頁框處為三個頁框
1. 先進先出(FIFO):共15次分頁錯誤
|
1 |
3 |
2 |
4 |
2 |
1 |
4 |
6 |
2 |
1 |
4 |
3 |
7 |
6 |
3 |
2 |
1 |
2 |
3 |
6 |
分頁表 |
1 |
1 |
1 |
4 |
4 |
4 |
4 |
4 |
2 |
2 |
2 |
2 |
7 |
7 |
7 |
7 |
1 |
1 |
1 |
1 |
|
3 |
3 |
3 |
3 |
1 |
1 |
1 |
1 |
1 |
4 |
4 |
4 |
6 |
6 |
6 |
6 |
6 |
3 |
3 |
|
|
|
2 |
2 |
2 |
2 |
2 |
6 |
6 |
6 |
6 |
3 |
3 |
3 |
3 |
2 |
2 |
2 |
2 |
6 |
|
載入時間 |
0 |
1 |
2 |
0 |
1 |
2 |
3 |
4 |
0 |
1 |
2 |
3 |
0 |
1 |
2 |
3 |
0 |
1 |
2 |
3 |
|
0 |
1 |
2 |
3 |
0 |
1 |
2 |
3 |
4 |
0 |
1 |
2 |
0 |
1 |
2 |
3 |
4 |
0 |
1 |
|
|
|
0 |
1 |
2 |
3 |
4 |
0 |
1 |
2 |
3 |
0 |
1 |
2 |
3 |
0 |
1 |
2 |
3 |
0 |
|
步驟
分頁錯誤,載入的分頁 (上一階段當中,載入時間最長的一個分頁)
檢查到已經有載入的分頁
|
||||||||||||||||||||
2. 最近最少使用(LRU):共15次分頁錯誤
|
1 |
3 |
2 |
4 |
2 |
1 |
4 |
6 |
2 |
1 |
4 |
3 |
7 |
6 |
3 |
2 |
1 |
2 |
3 |
6 |
分頁表 |
1 |
1 |
1 |
4 |
4 |
4 |
4 |
4 |
4 |
1 |
1 |
1 |
7 |
7 |
7 |
2 |
2 |
2 |
2 |
2 |
|
3 |
3 |
3 |
3 |
1 |
1 |
1 |
2 |
2 |
2 |
3 |
3 |
3 |
3 |
3 |
3 |
3 |
3 |
3 |
|
|
|
2 |
2 |
2 |
2 |
2 |
6 |
6 |
6 |
4 |
4 |
4 |
6 |
6 |
6 |
1 |
1 |
1 |
6 |
|
未被使 |
0 |
1 |
2 |
0 |
1 |
2 |
0 |
1 |
2 |
0 |
1 |
2 |
0 |
1 |
2 |
0 |
1 |
0 |
1 |
2 |
|
0 |
1 |
2 |
3 |
0 |
1 |
2 |
0 |
1 |
2 |
0 |
1 |
2 |
0 |
1 |
2 |
3 |
0 |
1 |
|
|
|
0 |
1 |
0 |
1 |
2 |
0 |
1 |
2 |
0 |
1 |
2 |
0 |
1 |
2 |
0 |
1 |
2 |
0 |
|
步驟
分頁錯誤,載入的分頁 (上一階段當中,未被使用時間最長的一個分頁)
檢查到已經有載入的分頁
|
||||||||||||||||||||
3. 第二次機會(Second=Chance Algorithm):共14次分頁錯誤
|
1 |
3 |
2 |
4 |
2 |
1 |
4 |
6 |
2 |
1 |
4 |
3 |
7 |
6 |
3 |
2 |
1 |
2 |
3 |
6 |
分頁表 |
1 |
1 |
1 |
4 |
4 |
4 |
4 |
4 |
4 |
1 |
1 |
1 |
7 |
7 |
7 |
2 |
2 |
2 |
2 |
2 |
|
3 |
3 |
3 |
3 |
1 |
1 |
6 |
6 |
6 |
4 |
4 |
4 |
6 |
6 |
6 |
1 |
1 |
1 |
6 |
|
|
|
2 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
3 |
3 |
3 |
3 |
3 |
3 |
3 |
3 |
3 |
|
載入時間 |
0 |
1 |
2 |
0 |
1 |
2 |
3 |
0 |
1 |
0 |
1 |
2 |
0 |
1 |
2 |
0 |
1 |
2 |
3 |
0 |
|
0 |
1 |
2 |
3 |
0 |
1 |
0 |
1 |
2 |
0 |
1 |
2 |
0 |
1 |
2 |
0 |
1 |
2 |
0 |
|
|
|
0 |
1 |
2 |
3 |
4 |
0 |
1 |
0 |
1 |
0 |
1 |
2 |
3 |
0 |
1 |
2 |
3 |
0 |
|
參考位元 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
|
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
|
|
0 |
0 |
1 |
1 |
1 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
|
步驟
分頁錯誤,載入的分頁
檢查到已經有載入的分頁
受檢查,給予第二次機會的分頁
|
||||||||||||||||||||

Comments